Monitoreo operativo de FortiGate con NetMonitor: disponibilidad, HA, interfaces y sesiones
Contenido
- Una integración basada en estándares
- Inventario e información general del FortiGate
- Disponibilidad basada en el estado real del equipo
- MTTR, MTBF y Cambios de Configuración
- CPU y memoria
- Estado de fuentes de alimentación y ventiladores
- Interfaces físicas y lógicas
- Tráfico, promedio y tendencia por interfaz
- Alta disponibilidad y clústeres FortiGate
- Sesiones en tiempo real
- Capacity planning de sesiones
- Alertas operativas básicas
- NetMonitor como complemento del ecosistema Fortinet
- Tabla resumen
- Conclusión
- Próxima parte: VPN, enlaces, tráfico y correlación
- Preguntas frecuentes
El monitoreo operativo de FortiGate no debería limitarse a comprobar si el firewall responde. Un equipo puede estar disponible y, al mismo tiempo, presentar descartes en interfaces, pérdida de sincronización en un clúster HA, crecimiento sostenido de sesiones o degradación en componentes de hardware.
Una interfaz puede estar activa pero registrar descartes. Un clúster puede seguir prestando servicio con uno de sus miembros fuera de sincronismo. La tabla de sesiones puede crecer de manera sostenida hasta aproximarse a la capacidad máxima del equipo. Una fuente de alimentación puede fallar sin provocar una interrupción inmediata.
NetMonitor permite incorporar los FortiGate dentro de una plataforma de monitoreo multivendor que combina disponibilidad, desempeño, recursos, interfaces, alta disponibilidad y sesiones. El objetivo no es reemplazar las herramientas de administración, seguridad o análisis de Fortinet, sino complementarlas con una visión integral del entorno tecnológico, especialmente en infraestructuras compuestas por múltiples fabricantes.
Un FortiGate disponible no garantiza un servicio disponible
El firewall puede responder mientras una interfaz, un clúster, una tabla de sesiones o un componente de hardware presenta una condición que afecta la operación. El monitoreo debe observar el estado real del equipo, no solo su respuesta básica.
Una integración basada en estándares
NetMonitor obtiene información del FortiGate mediante SNMP v2c, SNMP v3, traps SNMP y API de FortiGate.
SNMP se utiliza para consultar el estado general del dispositivo, los recursos del sistema, las interfaces, las sesiones, los componentes de hardware y otras variables operativas. Los traps permiten recibir eventos generados por el propio FortiGate, reduciendo la dependencia de consultas periódicas para detectar cambios relevantes.
La frecuencia de monitoreo se ajusta según la criticidad del activo. Un FortiGate perimetral en un datacenter o en una sede crítica puede consultarse con mayor frecuencia que uno en una ubicación de menor impacto operativo.
La solución fue validada con FortiOS desde la rama 6.x hasta la 8.x, tanto en appliances físicos como en FortiGate-VM. También contempla entornos con VDOM, monitoreo de miembros individuales en clúster y representación del clúster como entidad lógica.
Inventario e información general del FortiGate
NetMonitor centraliza los datos de identificación y configuración del equipo: identificador del activo, descripción, modelo, número de serie, versión de firmware, SysName, ubicación, emplazamiento, dirección de gestión, cantidad de interfaces totales, interfaces en uso, VLAN configuradas, modo HA, nombre del clúster, prioridad, estado de autosincronización y método de balanceo de carga.
Esta información es especialmente valiosa en organizaciones con múltiples sedes o datacenters, porque vincula el inventario técnico con el estado operativo del equipo.

Información del dispositivo: versión de firmware, modo HA, cantidad de interfaces, VLAN y parámetros del clúster.
Disponibilidad basada en el estado real del equipo
Uno de los problemas habituales del monitoreo tradicional es interpretar la pérdida aislada de una consulta como una caída real del equipo.
NetMonitor utiliza el estado del equipo y su uptime para diferenciar una indisponibilidad efectiva de una pérdida puntual del paquete de monitoreo. Esto evita que microcortes, congestión momentánea o una consulta aislada sin respuesta distorsionen los indicadores de disponibilidad.
NetMonitor utiliza la disponibilidad para calcular el SLI del activo.
El sistema puede calcular:
- Disponibilidad histórica
- SLI del último mes y del año
- MTTR (tiempo medio de recuperación)
- MTBF (tiempo medio entre fallos)
- Cantidad de interrupciones y fecha del último cambio de estado
Los objetivos son configurables, pueden compararse con SLA contractuales e incluirse en informes periódicos. Las ventanas de mantenimiento se administran mediante calendario para excluir períodos planificados del cómputo de disponibilidad.
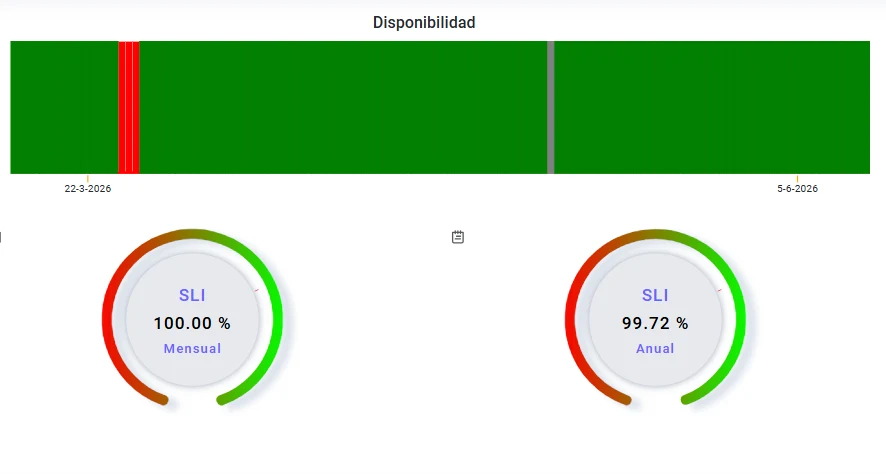
Historial de disponibilidad con indicadores SLI mensual y anual. Las barras rojas señalan períodos de indisponibilidad efectiva.
MTTR, MTBF y Cambios de Configuración
El MTBF (tiempo medio entre fallos) cuantifica la estabilidad histórica del equipo. Un MTBF en descenso puede indicar un patrón recurrente de interrupciones que requiere atención antes de convertirse en un problema de continuidad.
El MTTR refleja la eficiencia operativa del equipo ante una caída: cuánto tiempo transcurre en promedio desde que el equipo deja de responder hasta que vuelve a estar disponible.
Los cambios de configuración detectados nos permiten entender rápidamente si un problema de disponibilidad o de otra naturaleza tiene origen en una modificación en el FortiGate.

MTBF y MTTR calculados por NetMonitor. La última configuración detectada aparece resaltada y puede disparar un webhook hacia sistemas externos de backup.
CPU y memoria
NetMonitor registra la utilización de CPU y memorias con valores actuales, históricos, promedios, tendencias y umbrales configurables para alertas.
El valor técnico no reside únicamente en detectar un consumo puntualmente elevado. Lo relevante es observar el comportamiento en el tiempo y diferenciar un evento excepcional —como un pico por tráfico intenso o una operación de backup— de una tendencia sostenida que indica saturación estructural del equipo.
Un crecimiento progresivo de memoria puede anticipar una degradación antes de que el equipo presente síntomas. Un patrón periódico de CPU puede correlacionarse con procesos automáticos, cambios en el tráfico, reportes o tareas de seguridad programadas.
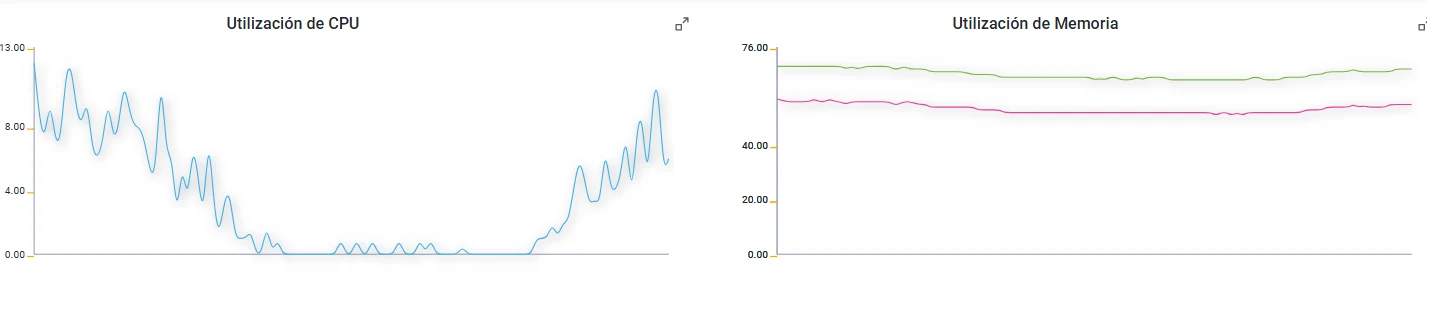
Utilización de CPU y memoria en el tiempo. La CPU refleja variaciones por actividad, mientras la memoria permanece estable en este ejemplo.
Estado de fuentes de alimentación y ventiladores
En equipos con componentes redundantes, una falla puede no interrumpir el servicio de manera inmediata pero elimina el margen de recuperación ante una segunda falla.
Un FortiGate puede continuar operando con una fuente defectuosa o con un ventilador fuera de rango, pero queda expuesto a una interrupción total si el componente restante también falla. Detectar esta condición con anticipación permite programar el reemplazo antes de que se produzca una caída no planificada.
NetMonitor puede supervisar el estado de fuentes de alimentación, ventiladores y otros sensores reportados por el FortiGate mediante SNMP, con alertas ante cualquier condición anormal.

Estado de fuentes de alimentación y ventiladores reportado vía SNMP. Las alertas se generan automáticamente ante cualquier condición anormal.
Interfaces físicas y lógicas
El monitoreo de interfaces es uno de los componentes más importantes para comprender el comportamiento operativo de un FortiGate.
NetMonitor puede representar todos los tipos de interfaz que el FortiGate puede configurar:
- Ethernet físicas
- Aggregate e interfaces LAG
- VLAN L3 y VLAN L2
- Bridge
- Túneles
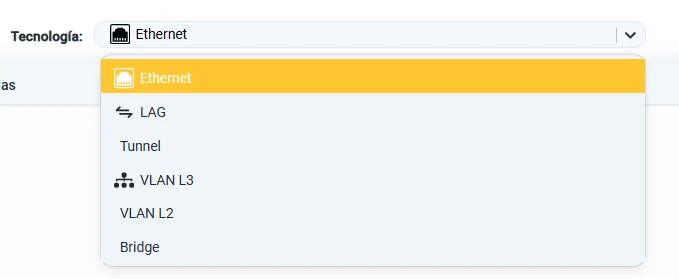
Tipos de interfaz disponibles para monitoreo: Ethernet, LAG, Tunnel, VLAN L3, VLAN L2 y Bridge.
Por cada interfaz pueden observarse: nombre, alias, tipo, dirección MAC, velocidad negociada, estado administrativo, estado operativo, último cambio de estado, tráfico entrante y saliente, promedios, mínimo, máximo, errores, descartes, cambios de velocidad y enlace asociado.
Una interfaz activa no necesariamente funciona correctamente. Puede registrar errores, descartes, flapping, saturación o un patrón anómalo de tráfico que solo es visible con monitoreo continuo.

Listado de interfaces con estado operativo, velocidad, último cambio y enlace asociado para correlación topológica.
Tráfico, promedio y tendencia por interfaz
Los gráficos por interfaz muestran tráfico de transmisión, recepción, promedio, tendencia, errores, descartes y evolución temporal. Esta vista permite identificar patrones diarios, horarios de mayor demanda, crecimientos graduales del baseline y eventos excepcionales.
La combinación de promedio y tendencia ayuda a comprender si el tráfico de una interfaz se mantiene estable, disminuye o crece. Esto resulta útil para evaluar capacidad, detectar picos, identificar horarios críticos y analizar el comportamiento de interfaces hacia enlaces WAN, switches o segmentos internos.
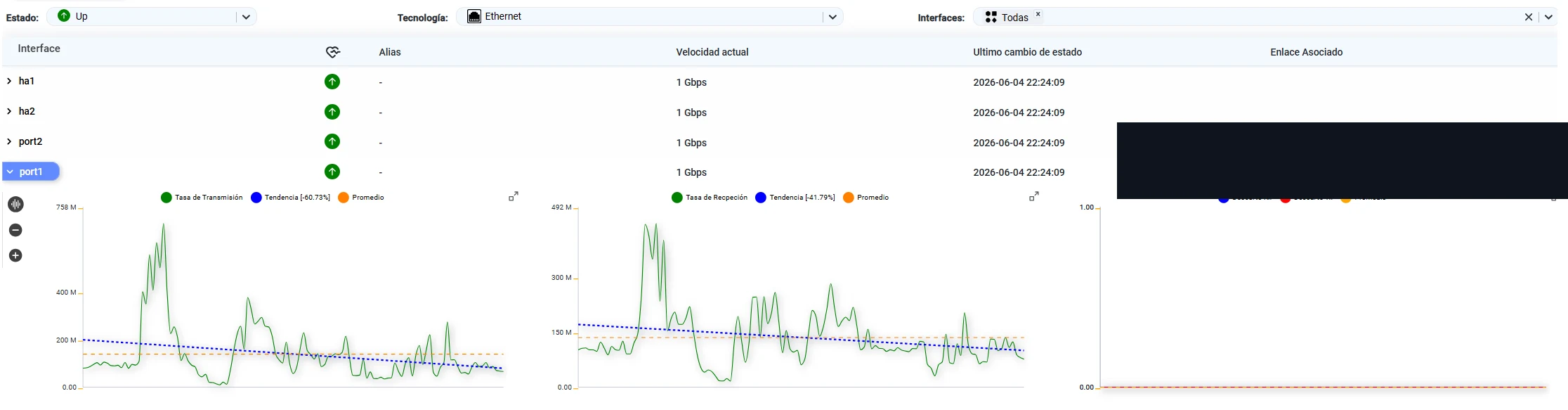
Histograma de tráfico por interfaz con transmisión, recepción, promedio, tendencia y descartes. La tendencia negativa indica reducción del tráfico en el período analizado.
Otra vista ofrece más información que incluye: datos generales, promedios, valores mínimos y máximos, historial de velocidad y registro de cambios detectados.
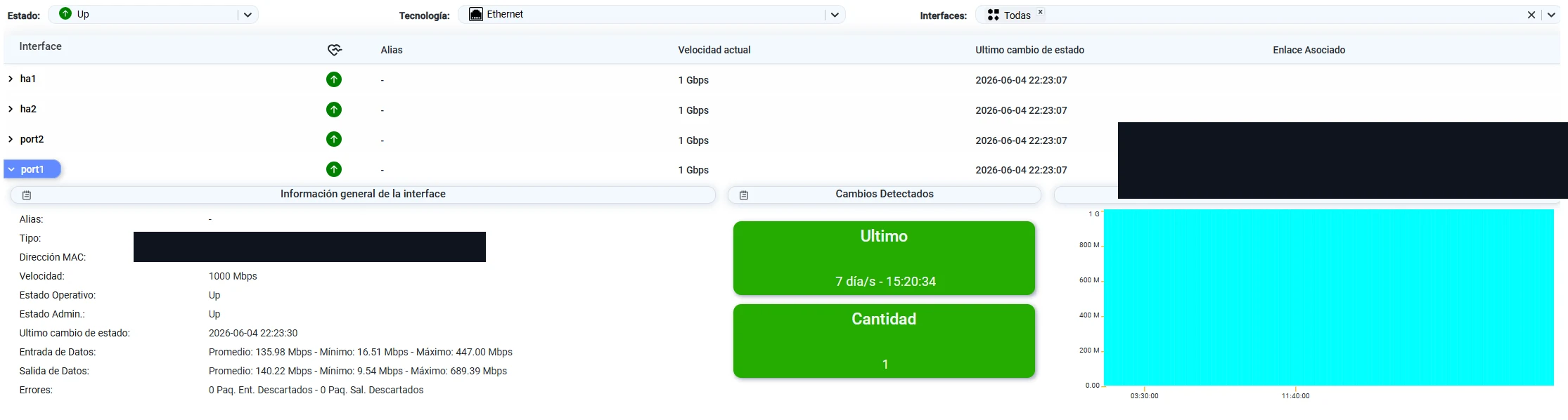
Vista detallada de interfaz: estadísticas completas, historial de velocidad y registro de cambios detectados.
Un cambio de velocidad en una interfaz es un evento que merece investigación. Puede indicar una negociación incorrecta, un problema con el cable o el puerto del switch remoto. La visibilidad histórica permite correlacionar ese evento con cualquier degradación de servicio observada en el mismo período.
Alta disponibilidad y clústeres FortiGate
En entornos críticos, el monitoreo del clúster debe contemplar tanto la entidad lógica (el servicio que presta el clúster) como cada miembro individual con sus propias métricas de recursos.
Monitorear el clúster y también sus miembros
Un clúster HA puede continuar operativo mientras uno de sus miembros está fuera de sincronismo. El servicio sigue disponible, pero la infraestructura perdió redundancia. Esta condición es invisible si solo se monitorea el servicio lógico.
NetMonitor puede mostrar, por cada miembro del clúster: identificador, etiqueta, ubicación, miembro primario activo, estado de sincronización, CPU, memoria, ancho de banda y sesiones.
Esta visibilidad permite detectar situaciones donde el servicio general continúa disponible, pero la redundancia se encuentra degradada:
- Un miembro no está sincronizado con el primario
- Un nodo presenta mayor consumo de memoria
- Se produjo un failover no planificado
- Un miembro tiene una cantidad anómala de sesiones
- El clúster continúa operativo, pero perdió tolerancia a fallas
NetMonitor puede generar alertas específicas ante pérdida de sincronismo entre miembros y ante eventos de failover.

Vista del clúster HA: estado de sincronización, CPU, memoria, ancho de banda y sesiones por miembro. Los datos de identificación fueron anonimizados.
Sesiones en tiempo real
La cantidad de sesiones es una métrica central en el análisis de capacidad y comportamiento de un FortiGate.
NetMonitor puede observar en tiempo real: utilización de CPU, memoria y sesiones concurrentes IPv4 e IPv6, sesiones nuevas por intervalo, promedios y evolución temporal de la carga de sesiones.
El monitoreo en tiempo real permite complementar el muestreo periódico, ofreciendo una visión de mayor granularidad para detectar picos anómalos de corta duración que podrían no quedar reflejados en las muestras habituales.
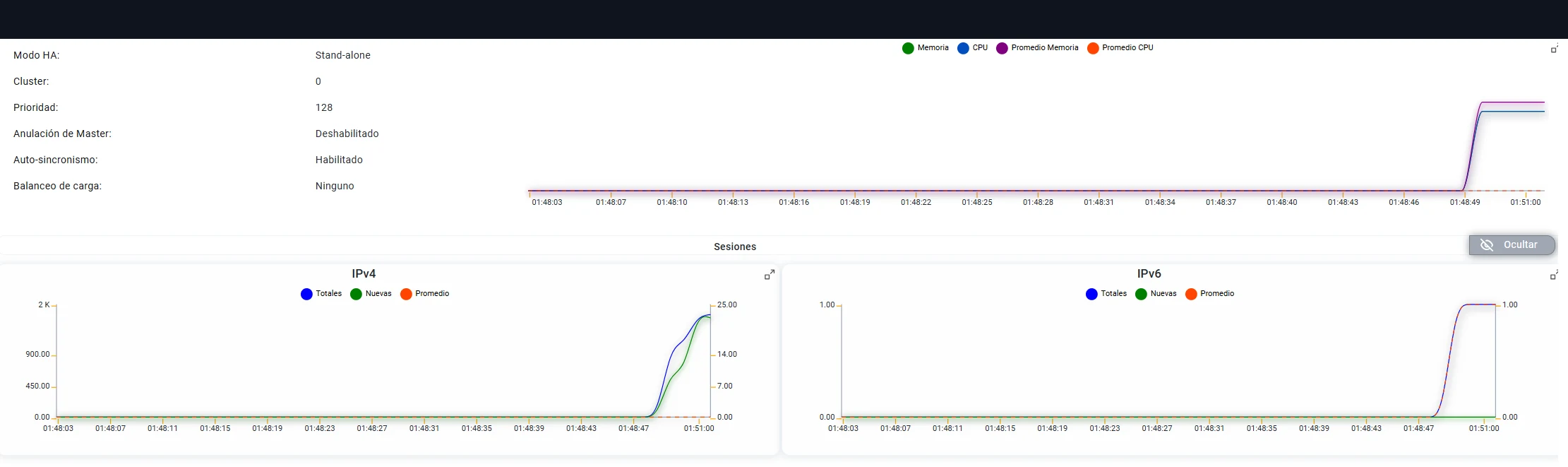
Sesiones IPv4 e IPv6 en tiempo real. El nombre del dispositivo fue anonimizado. El gráfico muestra el comportamiento de sesiones en el intervalo monitoreado.
La representación histórica de sesiones permite identificar los horarios de mayor demanda, patrones diarios recurrentes, cambios de comportamiento y crecimiento sostenido en el largo plazo.

Sesiones concurrentes (verde) y promedio (naranja punteado). El patrón muestra claramente los horarios de mayor actividad y el valle nocturno.
Capacity planning de sesiones
Monitorear el valor actual de sesiones no es suficiente para planificar capacidad. NetMonitor puede analizar el comportamiento histórico y presentar: histórico, promedio diario, tendencia, percentil y proyección.
El percentil 98 se utiliza para representar una condición de alta utilización sin basar todo el análisis en un único pico excepcional. Un evento atípico —un DDoS, una falla de routing que generó reconexiones masivas— no debería determinar por sí solo la decisión de capacidad del firewall. El percentil filtra esos eventos extremos y refleja la carga real sostenida del equipo.
La proyección es una estimación basada en el histórico acumulado y la tendencia observada. Su utilidad no es predecir con exactitud el futuro, sino detectar a tiempo si la tendencia actual llevará al equipo a su límite de sesiones en un horizonte de semanas o meses.
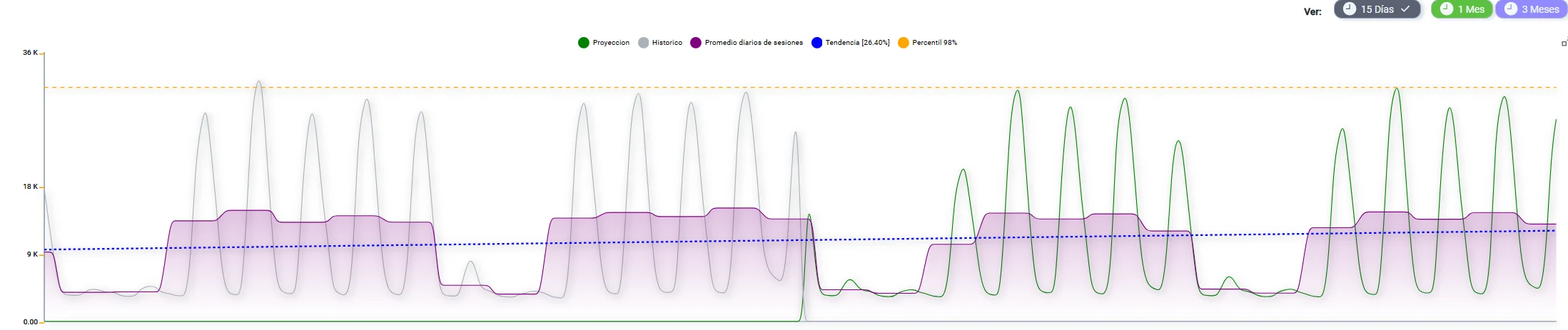
Histórico, promedio, tendencia, percentil 98 y proyección de sesiones. Esta vista permite anticipar necesidades de capacidad antes de que se conviertan en un incidente operativo.
Del valor actual al capacity planning
El histórico, los promedios, los percentiles y la tendencia permiten analizar la evolución de las sesiones y anticipar futuras necesidades de capacidad. La combinación de estos indicadores es más valiosa que cualquier lectura puntual.
Esta información puede utilizarse para evaluar el margen disponible en el equipo, anticipar crecimiento, identificar estacionalidad, justificar una ampliación de capacidad, revisar el licenciamiento o planificar una migración de modelo.
Alertas operativas básicas
NetMonitor puede generar alertas ante las condiciones operativas más relevantes de un FortiGate:
Disponibilidad y recursos:
Indisponibilidad del equipo, CPU por encima del umbral configurado, memoria alta, sesiones elevadas (en valor absoluto o como porcentaje de la capacidad del modelo).
Interfaces y conectividad:
Interfaz caída operativamente, errores por encima de umbral, descartes, cambio de velocidad en una interfaz.
Alta disponibilidad:
Pérdida de sincronización entre miembros del clúster, evento de failover.
Hardware:
Fuente de alimentación con falla o en estado degradado, ventilador con falla o fuera de rango.
SLA y tendencias:
SLI por debajo del objetivo configurado.
Identificación del evento raíz:
La configuración de dependencias entre activos permite suprimir alertas en cascada. Si el FortiGate perimetral de una sede está caído, NetMonitor puede generar una sola alerta identificando el evento raíz e incluyendo los activos afectados, como switches, access points, servidores y otros componentes dependientes.
NetMonitor como complemento del ecosistema Fortinet
Fortinet dispone de herramientas especializadas para cada disciplina: FortiManager para gestión centralizada y cambios de configuración, FortiAnalyzer para análisis de logs y eventos de seguridad, FortiSIEM para correlación de amenazas, FortiMonitor y FortiCloud para monitoreo nativo.
NetMonitor no busca reemplazar ninguna de estas plataformas. Su valor diferencial está en integrar el FortiGate dentro de una visión operativa y multivendor que incluye switches, routers, access points, servidores, sistemas OT, servicios de terceros y cualquier activo monitoreable por SNMP, ICMP, NetFlow, sFlow, API, entre otros.
En organizaciones con infraestructuras de múltiples fabricantes —Cisco, HPE Aruba, Juniper, Mikrotik, equipos OT— el FortiGate es una pieza más dentro de una cadena de disponibilidad que no puede analizarse de manera aislada. Un problema de latencia entre una sede y el datacenter puede originarse en el FortiGate, en el switch de borde, en el enlace WAN, en el gateway del proveedor o en algún punto intermedio.
NetMonitor permite construir esa visión completa, independientemente de quién fabricó cada pieza.
Tabla resumen
| Área | Información monitoreada | Valor operativo |
|---|---|---|
| Disponibilidad | Estado, uptime, SLI, MTTR y MTBF | Medir continuidad y cumplimiento de SLA |
| Inventario | Modelo, firmware, ubicación, interfaces y VLAN | Centralizar contexto técnico y operativo del activo |
| Recursos | CPU, memoria, fuentes y ventiladores | Detectar saturación y degradaciones de hardware |
| Interfaces | Estado, velocidad, tráfico, errores y descartes | Diagnosticar problemas de conectividad |
| Alta disponibilidad | Miembros, sincronización, primario, recursos y sesiones | Verificar redundancia y detectar failover |
| Sesiones | IPv4, IPv6, sesiones nuevas, histórico y proyección | Analizar carga y planificar capacidad |
| Alertas | CPU, memoria, interfaces, HA, hardware y SLI | Anticipar incidentes y priorizar acciones operativas |
Conclusión
Un FortiGate es una pieza crítica de la infraestructura, pero su funcionamiento no puede analizarse de manera aislada.
La disponibilidad del equipo es el punto de partida, no el punto de llegada. Una interfaz puede estar activa pero degradada. Un clúster puede seguir prestando servicio mientras uno de sus miembros ha perdido sincronismo. La tabla de sesiones puede estar creciendo de manera sostenida hacia el límite del equipo. Una fuente puede haber fallado sin que nadie lo detecte.
NetMonitor integra en una sola plataforma de monitoreo la disponibilidad, los recursos del sistema, las interfaces, la alta disponibilidad, las sesiones y el capacity planning, todo dentro de una visión operativa coherente y compatible con infraestructuras de múltiples fabricantes.
El resultado es una plataforma que complementa las herramientas del ecosistema Fortinet y extiende la observabilidad al resto del entorno tecnológico.
Próxima parte: VPN, enlaces, tráfico y correlación
En la segunda parte de esta serie se abordará cómo NetMonitor extiende la visibilidad del FortiGate hacia túneles VPN SSL e IPsec, monitoreo extremo a extremo de enlaces, caracterización de tráfico con NetFlow y sFlow, tabla ARP, dependencias e integración con sistemas de tickets y notificación.
Preguntas frecuentes sobre el monitoreo de FortiGate
¿NetMonitor reemplaza a FortiManager o FortiAnalyzer?
No. NetMonitor complementa las herramientas de Fortinet con una visión operativa y multivendor orientada a disponibilidad, interfaces, sesiones, recursos, SLI y capacidad.
¿Qué protocolos utiliza NetMonitor para monitorear FortiGate?
NetMonitor puede utilizar SNMP v2c, SNMP v3, traps SNMP y API de FortiGate para recopilar estado, recursos, interfaces, sesiones, hardware y eventos operativos.
¿Se puede monitorear un clúster HA FortiGate?
Sí. NetMonitor puede monitorear el clúster como entidad lógica y también cada miembro individual, incluyendo sincronización, CPU, memoria, ancho de banda y sesiones.
¿NetMonitor permite planificar capacidad en FortiGate?
Sí. A partir del histórico de sesiones, promedios, tendencia, percentiles y proyección, NetMonitor ayuda a identificar crecimiento sostenido y anticipar necesidades de capacidad.
Solicite una evaluación de su infraestructura FortiGate
Analizamos qué métricas, recursos, interfaces, clústeres y sesiones pueden incorporarse a NetMonitor para construir una visión operativa unificada de su infraestructura de red y seguridad.